Hadoop ignited a "Cambrian explosion," says its creator
forresters-hadoop-predictions-2015.jpg

Though streaming data tools like Apache Spark get all the press these days, batch-oriented processing tools like Hadoop will be around for a long, long time. While it's easy to assume that streaming will displace batch, the reality is much more nuanced, as Hadoop creator Doug Cutting stressed to me in an interview.
In fact, he notes that while Hadoop sparked a "Cambrian explosion" of big data innovation, we're settling into an era "of more normal evolution, as use of these technologies now spreads through industries."
Batch is(n't) best
While the industry likes to sneer at batch, Cutting and others didn't settle on batch processing because some cabal of coders decided it was the optimal way to deal with data. Rather, as Cutting informed me, it was simply the best place to start:
"It wasn't as though Hadoop was architected around batch because we felt batch was best. Rather, batch, MapReduce in particular, was a natural first step because it was relatively easy to implement and provided great value. Before Hadoop, there was no way to store and process petabytes on commodity hardware using open-source software. Hadoop's MapReduce provided folks with a big step in capability."
Looking back, it's hard to argue with how the industry has evolved. The industry has needed to walk with batch before it could run with streaming data. Back in 2012, I joined real-time analytics vendor Nodeable. Less than a year later, we had to sell the company, as the market for real time hadn't caught up to its promise.
But even in the more comfortable world of batch-oriented Hadoop, the industry is still slow to embrace big data. According to a 2014 Gartner survey, more enterprises are moving into big data pilots and production:
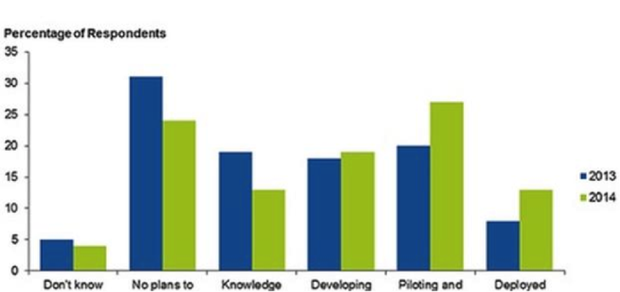
figa-gartnersurvey.png

At the same time, there remains a dearth of understanding of how to effectively put these big data technologies to use to use. This helps to explain why Hadoop, despite being the most well-known big data technology, continues to account for just 3% of all enterprise storage, as 451 Research details.
As Datastax chief evangelist Patrick Mcfadin explained to me in an interview, "Google, Yahoo and Facebook make it sound amazing and sadly, enterprises are looking at how to apply that analytics hammer to all the data. First: collect all the data. Second:... Third: Profit!"
If only it were that easy.
A natural evolution
Part of the problem for enterprises is that big data has moved too fast. Spark, Kafka, MongoDB, Impala, Flume... big data today incorporates a dizzying array of weirdly named technologies that demand a CIO's full attention if she wants her company to remain current.
But for those enterprises that feel they've been left behind by big data's blistering pace, Cutting offers solace:
"I expect that major additions to the stack like [Apache] Spark will slow, that over time we'll stabilize on a set of tools that provide the range of capabilities that most folks demand for their big data applications. Hadoop ignited a Cambrian explosion of related projects, but we'll likely now enter a time of more normal evolution, as use of these technologies now spreads through industries."
While it would appear that sexy new technologies like Spark render Hadoop's MapReduce obsolete, the reality is much more nuanced. As Cutting continues, "There's no either/or, no rejection of what came before, but rather a filling out of potential as this open-source ecosystem has matured."
Patrick Wendell, software engineer at Databricks, agrees. As he informed me, while he doesn't "believe [streaming analytics] is over-hyped, per se," he still feels that "we are just at the beginning of what will likely be a major expansion of streaming workloads over the next few years."
Streaming workloads that won't obviate the need for batch, according to Cutting:
"I don't think there will be any giant shift towards streaming. Rather streaming now joins the suite of processing options that folks have at their disposal. When they need interactive BI, they use Impala, when they need faceted search, they use Solr, and when they need real-time analytics, they use Spark Streaming, etc. Folks will still perform retrospective batch analytics too. A mature user of the platform will likely use all of these."
The golden years of big data
Cutting's perspective makes sense in an enterprise world that is slow to embrace new technologies and just as slow to dump them. With Cobol and mainframes still haunting the halls of private datacenters, it's perhaps too much to expect enterprises to immediately adopt and then drop Hadoop as seemingly sexier technologies come along.
Indeed, a Deutsche Bank research note finds that "CIOs are now broadly comfortable with [Hadoop] and see it as a significant part of the future data architecture. We would expect significant $ commitments in [fiscal year 2015]."
Those same CIOs are likely to discover and grow cozy with Spark, too, as Cutting and Wendell suggest. But that coziness won't eliminate reliance on slower-moving Hadoop. Not in this decade, anyway.

