Meta releases its biggest 'open' AI model yet
Meta's latest open source AI model is its biggest yet.
Today, Meta said it is releasing Llama 3.1 405B, a model containing 405 billion parameters. Parameters roughly correspond to a model's problem-solving skills, and models with more parameters generally perform better than those with fewer parameters.
At 405 billion parameters, Llama 3.1 405B isn't the absolute largest open source model out there, but it's the biggest in recent years. Trained using 16,000 Nvidia H100 GPUs, it also benefits from newer training and development techniques that Meta claims makes it competitive with leading proprietary models like OpenAI's GPT-4o and Anthropic's Claude 3.5 Sonnet (with a few caveats).
As with Meta's previous models, Llama 3.1 405B is available to download or use on cloud platforms like AWS, Azure and Google Cloud. It's also being used on WhatsApp and Meta.ai, where it's powering a chatbot experience for U.S.-based users.
New and improved
Like other open and closed source generative AI models, Llama 3.1 405B can perform a range of different tasks, from coding and answering basic math questions to summarizing documents in eight languages (English, German, French, Italian, Portuguese, Hindi, Spanish and Thai). It's text-only, meaning that it can't, for example, answer questions about an image, but most text-based workloads — think analyzing files like PDFs and spreadsheets — are within its purview.
Meta wants to make it known that it is experimenting with multimodality. In a paper published today, researchers at the company write that they're actively developing Llama models that can recognize images and videos, and understand (and generate) speech. Still, these models aren't yet ready for public release.
To train Llama 3.1 405B, Meta used a dataset of 15 trillion tokens dating up to 2024 (tokens are parts of words that models can more easily internalize than whole words, and 15 trillion tokens translates to a mind-boggling 750 billion words). It's not a new training set per se, since Meta used the base set to train earlier Llama models, but the company claims it refined its curation pipelines for data and adopted "more rigorous" quality assurance and data filtering approaches in developing this model.
The company also used synthetic data (data generated by other AI models) to fine-tune Llama 3.1 405B. Most major AI vendors, including OpenAI and Anthropic, are exploring applications of synthetic data to scale up their AI training, but some experts believe that synthetic data should be a last resort due to its potential to exacerbate model bias.
For its part, Meta insists that it "carefully balance[d]" Llama 3.1 405B's training data, but declined to reveal exactly where the data came from (outside of webpages and public web files). Many generative AI vendors see training data as a competitive advantage and so keep it and any information pertaining to it close to the chest. But training data details are also a potential source of IP-related lawsuits, another disincentive for companies to reveal much.
In the aforementioned paper, Meta researchers wrote that compared to earlier Llama models, Llama 3.1 405B was trained on an increased mix of non-English data (to improve its performance on non-English languages), more "mathematical data" and code (to improve the model's mathematical reasoning skills), and recent web data (to bolster its knowledge of current events).
Recent reporting by Reuters revealed that Meta at one point used copyrighted e-books for AI training despite its own lawyers’ warnings. The company controversially trains its AI on Instagram and Facebook posts, photos and captions, and makes it difficult for users to opt out. What's more, Meta, along with OpenAI, is the subject of an ongoing lawsuit brought by authors, including comedian Sarah Silverman, over the companies’ alleged unauthorized use of copyrighted data for model training.
"The training data, in many ways, is sort of like the secret recipe and the sauce that goes into building these models," Ragavan Srinivasan, VP of AI program management at Meta, told TechCrunch in an interview. "And so from our perspective, we've invested a lot in this. And it is going to be one of these things where we will continue to refine it."
Bigger context and tools
Llama 3.1 405B has a larger context window than previous Llama models: 128,000 tokens, or roughly the length of a 50-page book. A model’s context, or context window, refers to the input data (e.g. text) that the model considers before generating output (e.g. additional text).
One of the advantages of models with larger contexts is that they can summarize longer text snippets and files. When powering chatbots, such models are also less likely to forget topics that were recently discussed.
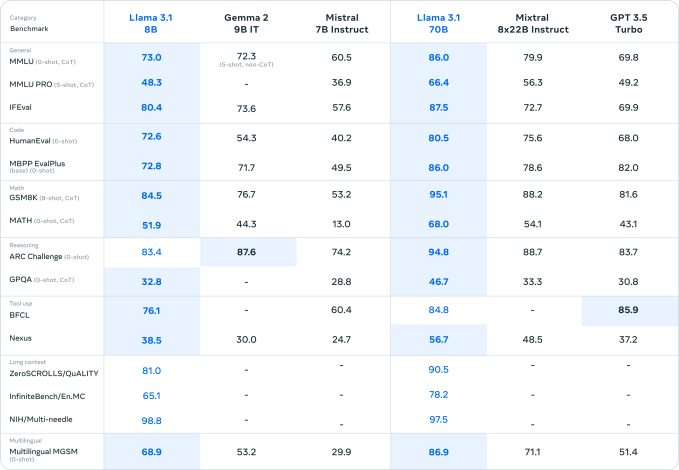
Two other new, smaller models Meta unveiled today, Llama 3.1 8B and Llama 3.1 70B — updated versions of the company's Llama 3 8B and Llama 3 70B models released in April — also have 128,000-token context windows. The previous models' contexts topped out at 8,000 tokens, which makes this upgrade fairly substantial -- assuming the new Llama models can effectively reason across all that context.
All of the Llama 3.1 models can use third-party tools, apps and APIs to complete tasks, like rival models from Anthropic and OpenAI. Out of the box, they're trained to tap Brave Search to answer questions about recent events, the Wolfram Alpha API for math- and science-related queries, and a Python interpreter for validating code. In addition, Meta claims the Llama 3.1 models can use certain tools they haven't seen before — to an extent.
Building an ecosystem
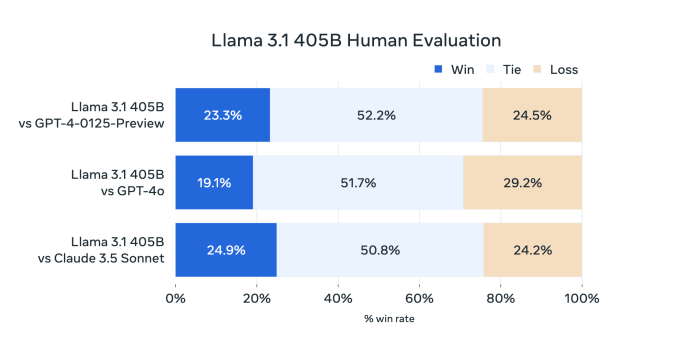
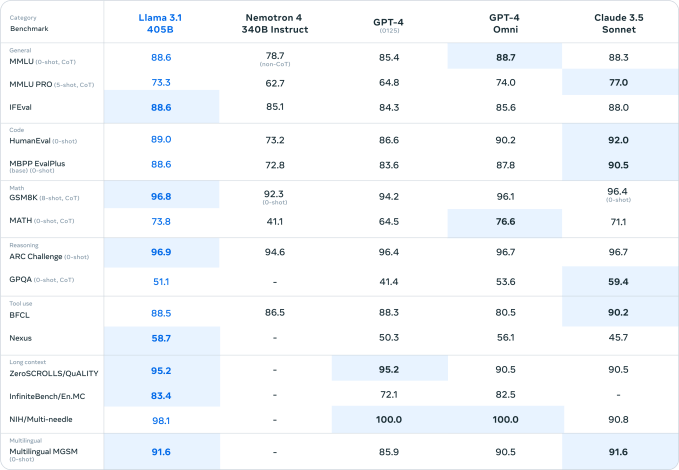
If benchmarks are to be believed (not that benchmarks are the end-all be-all in generative AI), Llama 3.1 405B is a very capable model indeed. That'd be a good thing, considering some of the painfully obvious limitations of previous-generation Llama models.
Llama 3 405B performs on par with OpenAI's GPT-4, and achieves "mixed results" compared to GPT-4o and Claude 3.5 Sonnet, per human evaluators that Meta hired, the paper notes. While Llama 3 405B is better at executing code and generating plots than GPT-4o, its multilingual capabilities are overall weaker, and Llama 3 405B trails Claude 3.5 Sonnet in programming and general reasoning.
And because of its size, it needs beefy hardware to run. Meta recommends at least a server node.
That's perhaps why Meta's pushing its smaller new models, Llama 3.1 8B and Llama 3.1 70B, for general-purpose applications like powering chatbots and generating code. Llama 3.1 405B, the company says, is better reserved for model distillation — the process of transferring knowledge from a large model to a smaller, more efficient model — and generating synthetic data to train (or fine-tune) alternative models.
To encourage the synthetic data use case, Meta said it has updated Llama's license to let developers use outputs from the Llama 3.1 model family to develop third-party AI generative models (whether that's a wise idea is up for debate). Importantly, the license still constrains how developers can deploy Llama models: App developers with more than 700 million monthly users must request a special license from Meta that the company will grant on its discretion.
That change in licensing around outputs, which allays a major criticism of Meta's models within the AI community, is a part of the company's aggressive push for mindshare in generative AI.
Alongside the Llama 3.1 family, Meta is releasing what it's calling a "reference system" and new safety tools — several of these block prompts that might cause Llama models to behave in unpredictable or undesirable ways — to encourage developers to use Llama in more places. The company is also previewing and seeking comment on the Llama Stack, a forthcoming API for tools that can be used to fine-tune Llama models, generate synthetic data with Llama and build "agentic" applications — apps powered by Llama that can take action on a user's behalf.
"[What] We have heard repeatedly from developers is an interest in learning how to actually deploy [Llama models] in production," Srinivasan said. "So we're trying to start giving them a bunch of different tools and options."
Play for market share
In an open letter published this morning, Meta CEO Mark Zuckerberg lays out a vision for the future in which AI tools and models reach the hands of more developers around the world, ensuring people have access to the "benefits and opportunities" of AI.
It's couched very philanthropically, but implicit in the letter is Zuckerberg's desire that these tools and models be of Meta's making.
Meta's racing to catch up to companies like OpenAI and Anthropic, and it is employing a tried-and-true strategy: give tools away for free to foster an ecosystem and then slowly add products and services, some paid, on top. Spending billions of dollars on models that it can then commoditize also has the effect of driving down Meta competitors' prices and spreading the company's version of AI broadly. It also lets the company incorporate improvements from the open source community into its future models.
Llama certainly has developers' attention. Meta claims Llama models have been downloaded over 300 million times, and more than 20,000 Llama-derived models have been created so far.
Make no mistake, Meta's playing for keeps. It is spending millions on lobbying regulators to come around to its preferred flavor of "open" generative AI. None of the Llama 3.1 models solve the intractable problems with today's generative AI tech, like its tendency to make things up and regurgitate problematic training data. But they do advance one of Meta's key goals: becoming synonymous with generative AI.
There are costs to this. In the research paper, the co-authors — echoing Zuckerberg's recent comments — discuss energy-related reliability issues with training Meta's ever-growing generative AI models.
"During training, tens of thousands of GPUs may increase or decrease power consumption at the same time, for example, due to all GPUs waiting for checkpointing or collective communications to finish, or the startup or shutdown of the entire training job," they write. "When this happens, it can result in instant fluctuations of power consumption across the data center on the order of tens of megawatts, stretching the limits of the power grid. This is an ongoing challenge for us as we scale training for future, even larger Llama models."
One hopes that training those larger models won't force more utilities to keep old coal-burning power plants around.

