The Scientists Who Cracked Google Translate for Whale Sounds

- Oops!Something went wrong.Please try again later.
The global mecca for whale-watching, Monterey Bay, is a short drive from the epicenter of the Information Age, San Francisco and Silicon Valley. In the summer of 2018, three years after my first fateful trip there, I was working just down the road from Britt [Selvitelle] and Aza [Raskin]. They drove down to our house, where my crew and I were staying during a film shoot. I had also invited Dr. John Ryan, a soft-spoken scientist in his fifties from the Monterey Bay Aquarium Research Institute with a penchant for skateboard- ing and roller coasters. John was already a believer in the power of AI to help explore whale sounds. Monterey Bay is cold; a feeding ground. It was thought that most humpback song happened far away, in their tropical breeding grounds. But John had a deep-sea listening station hooked up to his office, and he decided to trawl the recordings. It took hundreds of hours. To his astonishment he discovered the songs of hundreds of animals. John and his colleagues had then trained AIs, which made short work of six years of recordings, adding Blue and Fin whales to their listening skillset. They uncovered humpbacks singing in Monterey across nine months of the year. They learned the cold waters sometimes rang with whalesong for over twenty hours a day. John’s recordings covered the time Prime Suspect had been in Monterey. He told me that he bet our whale’s voice had been captured somewhere on his tapes. Sitting amid our stacked life vests, camera gyroscopes, charging batteries, and whirring hard drives, we ate fajitas and listened intently as Aza and Britt explained the plan they’d hatched. They were going to take the incredible computational power of the tech behind Google Translate and apply it to decoding animal communications.

To understand what the hell this meant, Britt and Aza had to give John and me a lesson in how AI had revolutionized translation. People had been using computers to translate and analyze language for decades; the field is known as natural language processing. Until recently, however, you had to laboriously teach the machine how to turn one human language into another. Computer programs were given decision trees to work through when faced with text in one language, and had to be instructed on what to do in every situation; they needed bilingual dictionaries and to be told the rules of grammar and so on. Writing these programs was time-consuming, and the results were rigid. Situations the programmers hadn’t anticipated would arise and crash the program, such as the computers’ inability to overcome misspellings.
Watch This Stunning Footage of Orca Whales Killing a Great White Shark
But then came two developments: The first was the blossoming of new AI tools, like artificial neural networks—the same computer programs based on structures in the human brain that Julie used to discover unique dolphin whistles. Especially powerful in this regard were neural networks arranged in multiple layers called deep neural networks (DNNs). The second development was that the internet had made enormous volumes of translated text data freely available—Wikipedia, film subtitles, the minutes of meetings of the EU and the UN, millions of documents carefully translated into many languages.
These texts were ideal fodder for DNNs. Engineers could feed the algorithms both halves of the translation and ask the DNN to translate between them, but without using any existing language rules. Instead, the DNNs could create their own. They could try lots of different ways of seeing how to get from one language to a correct translation in another, and they could gamble with probabilities, again and again. They could learn the patterns for how to correctly translate. When it worked, the DNN would remember and test if it would work in a different context. The machines were learning in much the same way Jinmo Park’s computer vision algorithm learned to match whale tail flukes for Happywhale. Jinmo didn’t need to teach his program what a whale was, or how humans match one tail fluke to another. He simply needed lots of labeled examples and enough further unlabeled data for his algorithms to run through over and over until it found a way to make the patterns match.
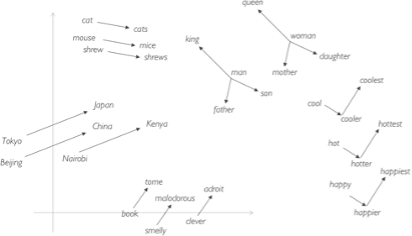
An example of word relationships in English.
While the first language-translation machines that used DNNs were decent, they were still nowhere near human competency. Most crucial, they still required our supervision: We had to give them examples of translation for them to work. Then came a very left-field development. In 2013, Tomas Mikolov, a computer scientist at Google, and his colleagues showed how, if you fed lots of texts to a different kind of neural network, you could ask it to look for patterns in the relationships between the words within a language. Similar or associated words would be placed close to each other, and dissimilar and less associated ones farther away. Aza quoted the linguist J. R. Firth: “You shall know a word by the company it keeps!”
For example, he explained: “ice” occurs often next to “cold,” but rarely does “ice” occur next to “chair.” This gives the computer a hint that “ice” and “cold” are semantically related in a way that “ice” and “chair” are not. Using written language to find these patterns of association, the neural network could embed each word into a map of the relationships of all the words in a language. I pictured this as a sort of star chart where each star was a word and each constellation within the galaxy of the language represented how those words were used relative to one another. It’s actually impossible to visualize these “galaxies,” as the numbers of words and their myriad geometric relationships mean they have hundreds of dimensions. But here is Britt and Aza’s example of the top ten thousand most spoken words in English compressed down to a 3D picture.
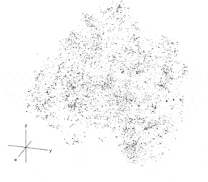
Each dot is one of the top ten thousand spoken words in English arranged as a galaxy of relationships.
What Mikolov and his colleagues discovered next was mind-blowing: you could do algebra on language! Britt and Aza broke it down: If you asked the program to take “king” and subtract “man” and add “woman,” the closest word in the cloud, the answer it produced was “queen.” It had not been taught what king or queen was, but it “knew” that a woman king was a queen. Even without knowing what a language meant, you could make a map of it and then explore it mathematically.
I was stunned. I’d always considered words and language as emotional, fuzzy, changeable things—and yet here was projected English, automatically assembled by a machine given billions of examples, into patterns of the relationships between words that we unthinkingly carry in our own heads, the harvest of our own neural networks from the big data of our own lives: the books, conversations, movies, and other information our brains have been fed and unconsciously tucked away.

This discovery was useful for finding relationships within a language, but what did it have to do with translation? This is the really neat part. In 2017 came a game-changing realization, one that had convinced Britt and Aza that these techniques could help with animal communications. A young researcher named Mikel Artetxe at the University of the Basque Country discovered that he could ask an AI to turn the word galaxies of different languages around, superimposing one onto another. And eventually, as if manipulating an absurdly complex game of Tetris, their shapes would match, the constellations of words would align, and if you looked at the same place in the German word galaxy where “king” sits in the English one, you would find “König.”
No examples of translation or other knowledge about either language was required for this to work. This was automatic translation with no dictionary or human input. As Britt and Aza put it, “Imagine being given two entirely unknown languages and that just by analyzing each for long enough you could discover how to translate between them.” It was a transformation of natural language processing.
And then came other new tools, too. Unsupervised learning techniques that worked on audio, in recordings of raw human speech, automatically identified what sounds were meaningful units—words. Other tools could look at word units and infer from their relationships how they were constructed into phrases and sentences—syntax. These were computer programs inspired by the circuitry of our brains, finding and linking patterns in our languages, which is how modern translation machines, like Google Translate, work today. And they work incredibly well, capable of translating sentences from English into Mandarin or Urdu, instantly and with reason- able accuracy. But how would they discover patterns in the communications of other animals?
For decades, humans have been trying to decode animal communication systems by looking for a Rosetta Stone—some sort of key to unlock them, a way into the unknown. Working with the smallest units, the simplest or most obvious vocalizations—like alarm calls and signature whistles—we attempted to identify a signal that might be meaningful to an animal, and then try to link it with a behavior to decode it. There was no other way, because we had no idea what any of the other sounds the animals were making meant—or if they had any meaning at all. Yet here was this new computer tool, unsupervised machine translation, that thrived despite not being instructed what any of the human languages it was given to translate meant. Britt and Aza didn’t need an automatic translation machine to interpret my facial expression when they told me this: holy crap. So would this work with animals? I asked them. Could you approach investigating animal “languages” by mapping all the vocalizations a species makes into a galaxy and comparing the patterns in these to the patterns in other species? Yes, they said. That was the plan.
My mind raced. If I understood this correctly, we could map animal communication systems as we have never been able to before. We could start exploring them in-depth by comparing them to one another. We could watch those communication galaxies change and evolve over time. We could inch outward from communication systems that share likely similarities, to those less similar. From comparing different families of fish-eating killer whales, to marine-mammal-eating killer whales, to pilot whales, to bottlenose dolphins, to blue whales, to elephants, to African grey parrots, gibbons, and humans. If—and it’s a big if—our automatic human- language-analysis tools worked at finding patterns in other species’ communication systems, they could help us construct a context for all animal communications. It could give us an idea of the diversity and number of galaxies in the communication universe and where we humans sit within it. Of course, the vocalizations of whales, dolphins, and other nonhumans might just be emotional noise, bereft of meaning, deep structure, or syntax. In which case, perhaps feeding lots of their communications into these algorithms would be like asking a facial recognition app to scan a pizza. But after all I’d learned, this felt unlikely. And even if cetaceans did have something like natural language, these techniques might still fail for other reasons.
One theory that explains why machine translations of human natural languages works so well is that all our languages are fundamentally capturing the same information. People living in Mongolia and Uganda live similar lives, in the sense that they perceive similar worlds, filled with similar objects and agents, with similar relationships, all bound by similar physics. Because the same things are therefore possible in these distant human worlds, their languages have ended up with a similar relational structure, allowing us to translate Swahili into Mongolian.

Whales and dolphins experience very different worlds to us, and if they have a world model captured in language, it is also likely to be very different. There may well be no similarities in the patterns of relationships between the units of humpback whale-speak and those of English, but knowing this would still be illuminating. Discovering rich, complex structures and relationships within nonhuman communication systems that bear no resemblance to those in human language would be a revelation in itself, hinting at parallel animal worldviews that we could explore. It’s language, Jim, but not as we know it.
For Britt and Aza, modern machine learning is a “fundamentally new tool,” for discerning patterns both within and between languages. A tool that could, in Aza’s words, allow us to “take off our human glasses.” I thought of Bob Williams and the Hubble telescope. Surely this, too, was worth a shot.
Excerpted from HOW TO SPEAK WHALE by Tom Mustill. Copyright © 2022 by Tom Mustill. Reprinted by arrangement with Grand Central Publishing. All rights reserved.
Get the Daily Beast's biggest scoops and scandals delivered right to your inbox. Sign up now.
Stay informed and gain unlimited access to the Daily Beast's unmatched reporting. Subscribe now.

